Javaプログラミングを学んでいると、Listはよく使うけれどMapは難しそう、と感じていませんか。
Javaの開発経験の中で、「データをどのように保持すればよいか分からない」「Listばかり使ってしまい、処理が遅くなる」という話をよく受けます。
多くの場合、その悩みはJavaのMapを正しく理解すると解決できます。Mapは、Listとはまったく異なる目的を持つ、非常に強力なデータ構造です。
この記事は、「JavaのMapについて基本から知りたい方」や「HashMapやLinkedHashMapの違いが分からない方」に向けて書いています。
この記事を読めばMapの基本構造、主要な4種類のMap(HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap)の特徴、そして実践的な使い方までを理解できます。
JavaのMapとは?基本の仕組みと役割
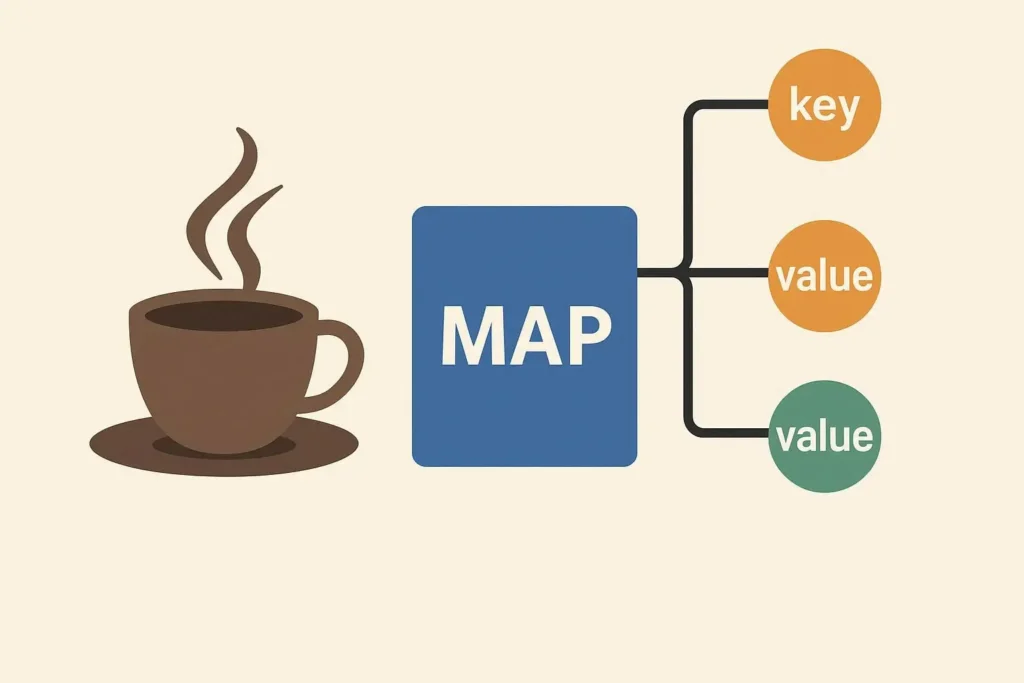
JavaのMapは、データを「ペア」で保存するための仕組みです。このペアは、キー (Key) と値 (Value) と呼ばれます。
Mapの最大の特徴は、キーを使って値を非常に高速に探し出せる点にあります。
Mapの「キーと値」の考え方
Mapを理解するうえで最も大切なのが、「キーと値」の考え方です。
これは、現実世界の「辞書」をイメージすると分かりやすいでしょう。
- キー (Key): 辞書で引く「単語」
- 値 (Value): その単語の「意味」
辞書では、調べたい単語(キー)さえ分かれば、すぐにその意味(値)を見つけられます。
JavaのMapも同じです。キーを指定すると、それに対応する値を一瞬で取得できます。
重要なルールが1つあります。それは、Mapの中ではキーは重複してはいけないというルールです。辞書に同じ単語が2つも3つも載っていないのと同じですね。もし同じキーで新しい値を追加しようとすると、古い値は上書きされます。
ListやSetとの違い
JavaにはMapの他にも、データをまとめるListやSetがあります。これらとMapの違いを理解することが重要です。
- List (例:
ArrayList)- 特徴: データを「順序通り」に並べて保存します。
- アクセス方法: 0番目、1番目、2番目… という「インデックス(位置番号)」でアクセスします。
- 値の重複: 許可されます。
- 使いみち: 順番が大切なデータ(例: 履歴、ランキング)に使います。
- Set (例:
HashSet)- 特徴: データを「重複しないように」保存します。
- アクセス方法: 決まった順序はなく、インデックスもありません。データが含まれているか「存在確認」することに特化しています。
- 値の重複: 許可されません。
- 使いみち: 重複を許さないデータの集まり(例: ユニークなユーザーID一覧)に使います。
- Map (例:
HashMap)- 特徴: データを「キーと値のペア」で保存します。
- アクセス方法: 「キー」を使って「値」を取得します。
- キーの重複: 許可されません。
- 使いみち: キーを使って特定の情報を「検索」したい場合(例: IDからユーザー情報を引く)に使います。
Listで特定のユーザーID(例えば "id_100")を持つユーザーを探す場合、Listの先頭から順に「このユーザーは "id_100" ですか?」と全員に聞いて回る必要があります。データが1,000,000件あれば、最悪1,000,000回の確認が必要です。
Mapを使えば、「"id_100" のユーザーをください」とMapに尋ねる(get("id_100"))だけで、一瞬で該当するユーザー情報を取得できます。

Mapが使われる代表的な場面
javamapは、以下のような「何かをキーにして、それに対応する情報を管理したい」場面で広く使われます。
- ユーザー情報の管理: ユーザーID(キー)とユーザーオブジェクト(値)
- 設定情報の管理: 設定名(キー)と設定値(値)
- APIレスポンスの表現: JSONデータのキーと値
- データの集計: 単語(キー)とその出現回数(値)
- キャッシュ: リクエストURL(キー)とレスポンスデータ(値)
「IDで検索する」「名前で検索する」といった処理が思い浮かんだら、それはMapの出番です。
JavaのMapの主な種類と特徴
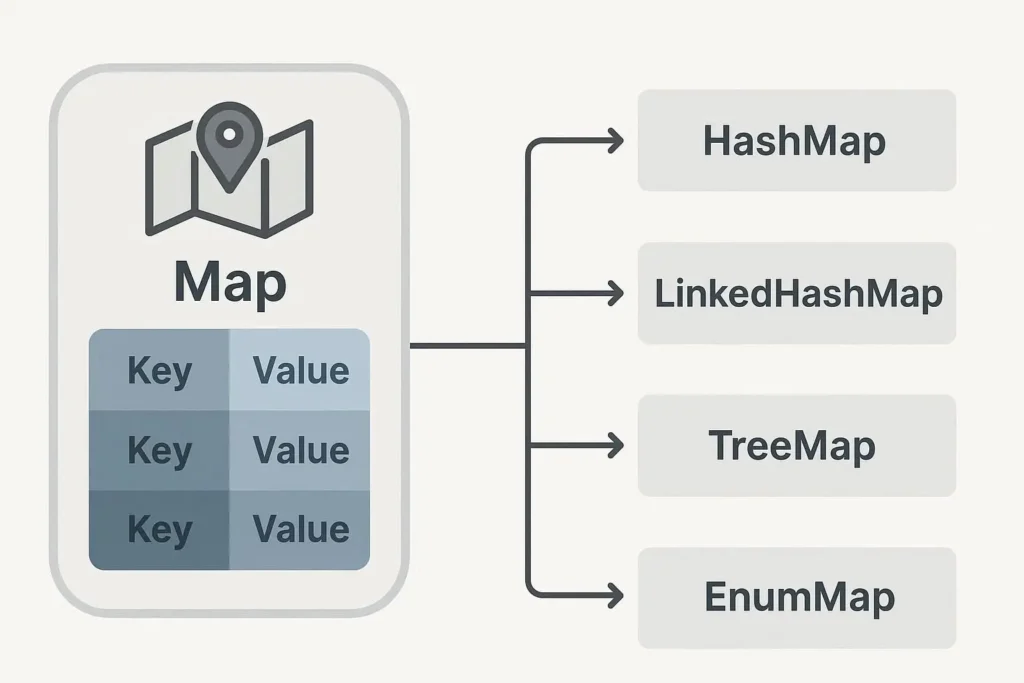
Mapは「こういう仕組みですよ」というルールです。実際に使うときは、そのルールを具体的に実現した「クラス」を使います。
ここでは、最もよく使われる4つのMapクラスを紹介します。
HashMap|最もよく使われるMap
HashMap(ハッシュマップ)は、JavaのMapの中で最も広く使われるクラスです。
「データの順序はどうでもよいので、とにかく速く追加・検索したい」という場合に、HashMapは第一候補となります。Hashmapはjava mapの基本です。
// HashMapの利用例
Map<String, String> capitals = new HashMap<>();
capitals.put("Japan", "Tokyo");
capitals.put("France", "Paris");
capitals.put("Germany", "Berlin");
// 順序は保証されない(実行するたびに順序が変わる可能性もある)
System.out.println(capitals);
// 出力例: {Japan=Tokyo, Germany=Berlin, France=Paris}LinkedHashMap|順序を保つMap
LinkedHashMap(リンクトハッシュマップ)は、HashMapの機能に「順序の保持」を追加したクラスです。
「Mapの高速な検索がしたい、でも追加した順番通りに取り出したい」という場合に最適です。
// LinkedHashMapの利用例
Map<String, String> capitals = new LinkedHashMap<>();
capitals.put("Japan", "Tokyo");
capitals.put("France", "Paris");
capitals.put("Germany", "Berlin");
// 追加した順序が保たれる
System.out.println(capitals);
// 出力: {Japan=Tokyo, France=Paris, Germany=Berlin}TreeMap|キーで自動ソートされるMap
TreeMap(ツリーマップ)は、キーを自動的に「ソート(並べ替え)」して保持するクラスです。
「キーで並べ替えた状態でデータを取り出したい」という場合にTreeMapを使います。
// TreeMapの利用例
Map<Integer, String> users = new TreeMap<>();
users.put(3, "Charlie");
users.put(1, "Alice");
users.put(2, "Bob");
// キー(数値)の昇順でソートされる
System.out.println(users);
// 出力: {1=Alice, 2=Bob, 3=Charlie}ConcurrentHashMap|マルチスレッド対応のMap
ConcurrentHashMap(コンカレントハッシュマップ)は、複数の処理(スレッド)から同時にアクセスされても安全に動作するように設計されたMapです。
HashMapを複数のスレッドから同時に変更しようとすると、データが壊れたり、無限ループに陥ったりする危険があります。ConcurrentHashMapは、高いパフォーマンスを維持しつつ、これを防ぎます。
Mapの基本操作を理解しよう
Mapの使い方は、どの種類(HashMapなど)でも共通です。ここではHashMapを例に、基本的な操作を見ていきましょう。
要素の追加・取得・削除の方法
Mapの最も基本的な操作は、データの「追加」「取得」「削除」の3つです。
要素の追加 (put)
put(キー, 値)メソッドを使います。
Map<String, Integer> scores = new HashMap<>();
// 要素の追加
scores.put("Alice", 90);
scores.put("Bob", 85);
scores.put("Carol", 95);
System.out.println(scores); // {Carol=95, Alice=90, Bob=85}
// 同じキーでputすると「上書き」される
scores.put("Alice", 92);
System.out.println(scores); // {Carol=95, Alice=92, Bob=85}要素の取得 (get)
get(キー)メソッドを使います。キーに対応する値が返されます。もしキーが存在しない場合はnullが返されます。
// "Bob"のスコアを取得
Integer bobScore = scores.get("Bob");
System.out.println(bobScore); // 85
// 存在しないキー ("David") を指定
Integer davidScore = scores.get("David");
System.out.println(davidScore); // null要素の削除 (remove)
remove(キー)メソッドを使います。キーと値のペアが削除されます。
// "Carol"のデータを削除
scores.remove("Carol");
System.out.println(scores); // {Alice=92, Bob=85}1要素数の取得 (size)
size()メソッドで、Mapに含まれるキーと値のペアの数を取得できます。
int count = scores.size();
System.out.println(count); // 2Mapのループ処理(for文・entrySet)
Mapに保存されたすべての要素を順番に取り出すには、いくつかの方法があります。
keySet() (キーの集まりでループ)
keySet()でキーのSetを取得し、各キーを使ってget()で値を取得します。
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90);
scores.put("Bob", 85);
// 1. keySet() を使ったループ
System.out.println("--- keySet() ---");
for (String name : scores.keySet()) {
Integer score = scores.get(name); // キーを使って値を取得
System.out.println(name + " : " + score);
}values() (値の集まりでループ)
キーは不要で、値だけが必要な場合はvalues()を使います。
// 2. values() を使ったループ (値のみ)
System.out.println("--- values() ---");
for (Integer score : scores.values()) {
System.out.println(score);
}entrySet() (キーと値のペアでループ) - 推奨
entrySet()は、「キーと値のペア(Entryオブジェクト)」のSetを返します。この方法が最も効率的です。
keySet()の方法では「キー一覧の取得」と「キーごとの値の取得」という2段階のアクセスが発生しますが、entrySet()なら1回のアクセスでキーと値の両方を取得できます。
// 3. entrySet() を使ったループ (推奨)
System.out.println("--- entrySet() ---");
for (Map.Entry<String, Integer> entry : scores.entrySet()) {
String name = entry.getKey(); // ペアからキーを取得
Integer score = entry.getValue(); // ペアから値を取得
System.out.println(name + " : " + score);
}forEach() (Java 8以降)
Java 8からはforEachとラムダ式を使って、より簡潔に書けます。
// 4. forEach (Java 8+)
System.out.println("--- forEach() ---");
scores.forEach((name, score) -> {
System.out.println(name + " : " + score);
});キーや値の存在チェック方法
Mapに特定のキーや値があるかを確認する方法です。
キーの存在チェック (containsKey)
containsKey(キー)を使います。非常に高速です。
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90);
scores.put("Bob", null); // Bobの値は null
// "Alice" というキーは存在するか?
boolean hasAlice = scores.containsKey("Alice");
System.out.println(hasAlice); // true
// "David" というキーは存在するか?
boolean hasDavid = scores.containsKey("David");
System.out.println(hasDavid); // falseget(キー) != null で存在チェックをしてはいけません。なぜなら、上記の "Bob" のように「キーは存在するが、値がnull」の場合に、get("Bob")はnullを返し、存在しないと誤判定してしまうからです。キーの存在確認は必ずcontainsKeyを使いましょう。
値の存在チェック (containsValue)
containsValue(値)を使います。
// 90 という値は存在するか?
boolean has90 = scores.containsValue(90);
System.out.println(has90); // true
// 70 という値は存在するか?
boolean has70 = scores.containsValue(70);
System.out.println(has70); // false注意: containsValueは、Map内のすべての値を順に調べるため、処理が遅くなります。データ件数が多い場合は、この操作を頻繁に行う設計を避けるべきです。
Mapを使うときの注意点とよくあるエラー
Mapは便利ですが、いくつか注意点があります。特にHashMapを使う場合は、以下の3点を押さえてください。
Nullキー・Null値の扱い
Mapの種類によって、nullをキーや値として扱えるかが異なります。
| クラス | nullキー | null値 |
| HashMap | 1つ許可 | 複数許可 |
| LinkedHashMap | 1つ許可 | 複数許可 |
| TreeMap | 不可 (例外発生) | 許可 |
| ConcurrentHashMap | 不可 (例外発生) | 不可 (例外発生) |
HashMapはnullを許容しますが、ConcurrentHashMapやTreeMapはnullを入れようとするとNullPointerExceptionというエラーが発生します。使うMapの特性を理解しておくことが大切です。
順序が保証されないMapに注意
これは初心者が最も陥りやすい罠の一つです。
HashMapは順序を保証しません。
テスト環境でHashMapに (A, B, C) とデータを入れたとき、たまたま (A, B, C) の順序で取り出せることがあります。しかし、それは「たまたま」です。データの件数が変わったり、実行環境が変わったりすると、(B, A, C) や (C, B, A) のように順序が変わる可能性があります。
「追加した順序」が必要な場合は、必ずLinkedHashMapを使います。
「キーでソートされた順序」が必要な場合は、必ずTreeMapを使います。
順序をHashMapに期待してはいけません。
equalsとhashCodeの関係
HashMap(やHashSet)を正しく使ううえで、最も重要で、最も難しい概念が「equalsとhashCode」の関係です。
StringやIntegerなど、Javaが最初から用意しているクラスをキーに使う場合は問題ありません。
問題が起きるのは、自作のクラス(例: Studentクラス)をMapのキーとして使う場合です。
HashMapは、「ハッシュコード (hashCode)」という数値を使って、キーを高速に探します。
あなたがStudentクラスをキーにしたい場合、そのStudentクラスでequals()と hashCode()(そのオブジェクトのハッシュコードを返すメソッド)の2つを正しく実装(オーバーライド)する必要があります。
守るべきルール
equals() で true になる2つのオブジェクトは、必ず同じ hashCode() の値を返さなければならない。
もしこのルールを守らないと、HashMapは正しく動作しません。
悪い例: equalsとhashCodeを実装していない
// 自作のStudentクラス (悪い例)
class Student {
private String id;
public Student(String id) { this.id = id; }
// equals() と hashCode() がない!
}
Map<Student, String> map = new HashMap<>();
Student s1 = new Student("001");
map.put(s1, "Alice"); // s1 (ID "001") をキーにして "Alice" を保存
// 見た目は同じID "001" の s2 を作成
Student s2 = new Student("001");
// s2 で値を取り出そうとする
String name = map.get(s2);
// equals/hashCodeが未実装だと、s1とs2は「別物」と判断される
System.out.println(name); // null (取れない!)HashMapから見ると、s1とs2は(IDが同じでも)別のオブジェクトであり、ハッシュコードも異なるため、s2に対応する値は見つからない、と判断されてしまいます。
良い例: equalsとhashCodeを正しく実装
// 自作のStudentクラス (良い例)
class Student {
private String id;
public Student(String id) { this.id = id; }
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Student student = (Student) obj;
return id.equals(student.id); // IDが同じなら「等しい」
}
@Override
public int hashCode() {
return id.hashCode(); // IDが同じなら同じハッシュコードを返す
}
}
// (同じコード)
Map<Student, String> map = new HashMap<>();
Student s1 = new Student("001");
map.put(s1, "Alice");
Student s2 = new Student("001");
String name = map.get(s2);
// 正しく実装されていれば、s1とs2は「等しい」と判断される
System.out.println(name); // Alice (正しく取れる!)自作クラスをHashMapやHashSetのキーにするときは、equalsとhashCodeを必ずセットで実装することを忘れないでください。
Mapを使った実践コード例
Mapが実際のコードでどのように使われるか、3つの例を見てみましょう。
学生の成績管理をMapで表現する
学生の「名前(キー)」と「点数(値)」を管理するのにMapは最適です。
// キー: 名前 (String), 値: 点数 (Integer)
Map<String, Integer> studentScores = new HashMap<>();
// 成績の登録
studentScores.put("Alice", 90);
studentScores.put("Bob", 85);
studentScores.put("Charlie", 98);
// Bobの成績を更新
studentScores.put("Bob", 88);
// 特定の学生の成績を取得
Integer aliceScore = studentScores.get("Alice");
System.out.println("Aliceの点数: " + aliceScore); // Aliceの点数: 90
// 全員の成績一覧を出力 (entrySetを使用)
System.out.println("--- 成績一覧 ---");
for (Map.Entry<String, Integer> entry : studentScores.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue() + "点");
}APIレスポンスをMapで整理する
Web APIからJSON形式でデータが返ってくることはよくあります。JSONとMapは非常に相性が良いです。
例えば、以下のようなJSONレスポンスを受け取ったとします。
{ "id": 123, "username": "admin", "isActive": true }
これはMap<String, Object>で表現できます。
// APIからのJSONレスポンスをMapで表現 (GsonやJacksonなどのライブラリ使用を想定)
Map<String, Object> apiResponse = new HashMap<>();
apiResponse.put("id", 123);
apiResponse.put("username", "admin");
apiResponse.put("isActive", true);
// ユーザー名を取得
String username = (String) apiResponse.get("username");
System.out.println("ユーザー名: " + username); // ユーザー名: admin
// IDを取得
Integer id = (Integer) apiResponse.get("id");
System.out.println("ID: " + id); // ID: 123値の型がStringやIntegerなど様々なので、値の型はObjectとしておき、取り出すときに適切な型にキャスト(変換)します。
Mapを使った簡単な集計処理
Mapは「集計」にも威力を発揮します。例えば、文章中の単語の出現回数を数える処理です。
String text = "java map is useful. java is powerful.";
// 単語を空白とピリオドで区切る
String[] words = text.split("[ .]+"); // [java, map, is, useful, java, is, powerful]
// キー: 単語 (String), 値: 出現回数 (Integer)
Map<String, Integer> wordCounts = new HashMap<>();
// 単語をループして集計
for (String word : words) {
// 1. その単語の現在のカウントを取得
Integer count = wordCounts.get(word);
if (count == null) {
// 2. Mapにまだ登録されていなければ (初回)、カウント 1 で登録
wordCounts.put(word, 1);
} else {
// 3. すでに登録されていれば、カウントを +1 して上書き
wordCounts.put(word, count + 1);
}
}
System.out.println(wordCounts);
// 出力: {powerful=1, useful=1, map=1, java=2, is=2}
// Java 8以降では getOrDefault を使うと、if文なしで簡潔に書けます
for (String word : words) {
wordCounts.put(word, wordCounts.getOrDefault(word, 0) + 1);
}まとめ|Mapを理解すればJavaのデータ構造がわかる
Mapは、キーを使って値を高速に検索するためのデータ構造です。Listが「順番」に特化しているのに対し、Mapは「検索」に特化しています。
Mapを使いこなすためのポイント再確認
Mapは「キーと値のペア」でデータを保存します。- 速度なら
HashMap: 順序は不要で、とにかく速さを求める場合。 - 挿入順序なら
LinkedHashMap: 追加した順番通りに取り出したい場合。 - ソート順なら
TreeMap: キーで自動的に並べ替えたい場合。 - ループ処理は
entrySet()が最も効率的です。 - 自作クラスをキーにする 場合は、
equals()とhashCode()を必ず正しく実装してください。
Listしか使ったことがない状態から、Mapを適切な場面で使えるようになると、Javaプログラミングのレベルが一段上がります。