Spring Batchは、Javaの大量データ一括処理で最も広く使われるバッチフレームワークです。この記事では、Spring Boot 3〜4・Spring Batch 5〜6に対応した基本構造(Job・Step・Chunk)から、実務で欠かせないリトライ・再実行の設計まで体系的に解説します。
Javaエンジニアとして10年以上、基幹システムのバッチ処理と向き合ってきました。夜中の「バッチが止まった」アラートに何度も対処した経験をもとに、運用まで見据えた設計のコツをお伝えします。
独自のシェルスクリプトやwhileループで消耗している方、Spring Batchを使い始めたもののJobの再実行やChunkサイズの決め方で悩んでいる方は、ぜひ参考にしてください。
Spring Batchとは何か?バッチ処理の基本と役割を整理する
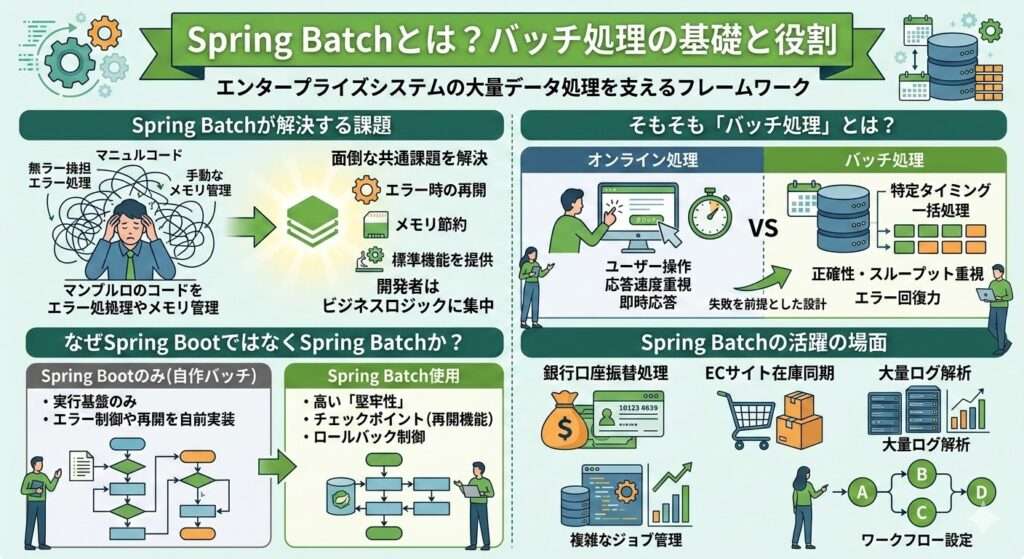
Spring Batchは、エンタープライズシステムに不可欠な「大量データの定型処理」を効率的に行うためのフレームワークです。単に「裏側で動くプログラム」を作るための道具ではありません。エラーが起きたときにどこからやり直すか、大量のメモリをどう節約するかといった、バッチ処理における「面倒な共通課題」を解決するために存在しています。
そもそもバッチ処理とは何をする仕組みなのか
バッチ処理は、ユーザーの操作を介さずに、特定のタイミングで大量のデータを一括処理する仕組みを指します。例えば、1日の売上データを夜間に集計してレポートを作成したり、数百万件の顧客情報を別のデータベースへ移行したりする作業が該当します。
オンライン処理(画面からの操作)との最大の違いは、応答速度よりも「正確性」と「スループット(処理能力)」が重視される点にあります。途中でエラーが起きても、それまでに処理したデータを壊さず、かつ効率よく再開できる仕組みが求められるのです。
Spring BootとSpring Batchの違い|なぜBatchを使うのか
Spring Bootだけでバッチ風の処理を書くことは可能ですが、Spring Batchを使うべき理由は「堅牢性」のレベルが違うからです。Spring Bootはあくまでアプリケーションを実行するための基盤に過ぎません。
自作のループ処理では、エラー時のロールバック範囲の制御や、中断した場所からの再開(チェックポイント)の実装をすべて自前で行う必要があります。Spring Batchは、これらの「失敗を前提とした設計」を標準機能として提供してくれるため、開発者はビジネスロジックに集中できるのが最大の利点です。
Spring Batchが選ばれる代表的な利用シーン
Spring Batchが本領を発揮するのは、データ量が数万件を超え、処理に失敗したときの影響が大きい場面です。代表的なユースケースは以下の通りです。
- 銀行の口座振替処理
- ECサイトの在庫同期
- 大量のログ解析
また、複雑な依存関係を持つジョブの管理にも適しています。「Aの処理が終わってからBとCを並列で動かし、最後にDで締める」といったワークフローを、設定レベルで管理できる柔軟性があるため、大規模開発では欠かせない存在となっています。
Spring Batchの全体像をつかむ:Job・Step・Chunkの関係
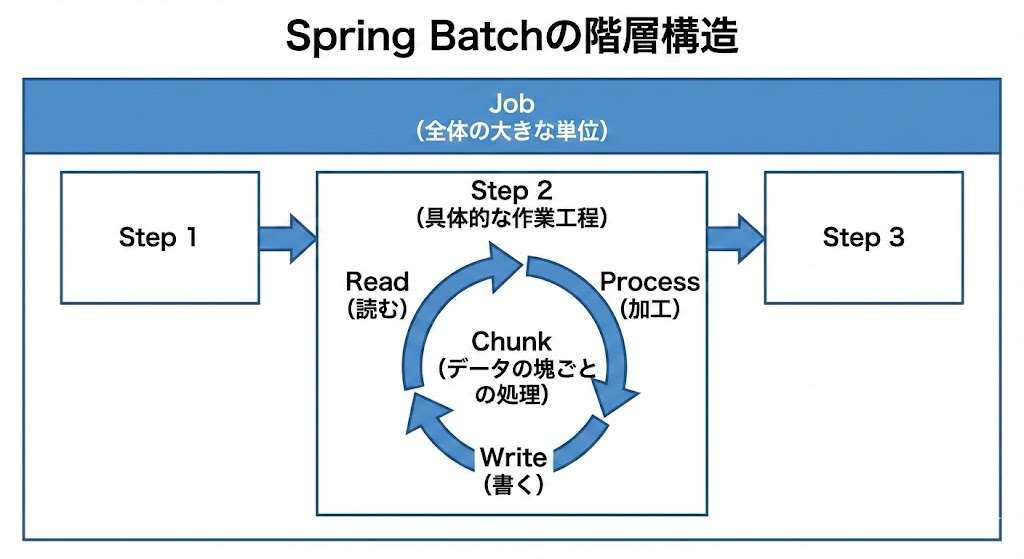
Spring Batchを理解する上で最も重要なのは、その「階層構造」を把握することです。全体を俯瞰すると、1つの大きな単位である「Job」があり、その中に具体的な作業工程である「Step」が含まれるという構造になっています。
この構造を理解せずにコードを書き始めると、どこに何を記述すべきか迷子になってしまいます。
JobとStepの役割と実行の流れ
Jobは、バッチ処理全体を指すコンテナのような役割を果たします。「月次売上集計」や「顧客データ移行」といった名前がつく単位です。これに対し、StepはJobを構成する個別の工程を指します。
1つのJobの中には、複数のStepを定義できます。工程を細かく分けることで、再利用性やメンテナンス性が向上します。例えば、以下のように分割するのが典型的なパターンです。
- Step1: CSVファイルを読み込む
- Step2: データを加工してDBに保存する
- Step3: 完了通知メールを送る
実行時は、定義された順番に従ってStepが1つずつ消化されていきます。
Chunkモデルとは何か(なぜ分割して処理するのか)
Spring Batchの真髄とも言えるのが「Chunk(チャンク)モデル」です。これは、大量のデータを一定数(例えば100件ずつ)の塊に分けて処理する方式です。なぜわざわざ小分けにするのでしょうか。
最大の理由は、メモリ消費の抑制とトランザクションの最適化です。100万件のデータを一度にリストへ読み込むと、メモリ不足でサーバーがダウンしてしまいます。Chunkモデルなら、100件処理するごとにコミットを行い、メモリを解放します。万が一エラーが起きても、直前の100件分だけをやり直せば済むため、被害を最小限に抑えられるのです。
ItemReader・ItemProcessor・ItemWriterの責務
ChunkモデルによるStepは、3つの登場人物で構成されます。まず「ItemReader」がデータを1件ずつ読み込みます。次に「ItemProcessor」がそのデータを加工や変換、チェックを行います。最後に、一定数(Chunkサイズ)まで溜まったデータを「ItemWriter」が一括で出力します。
- ItemReader: DB、ファイル、メッセージキューなどからデータを取得する。
- ItemProcessor: ビジネスロジックを詰め込む場所。不要なデータのフィルタリングも行う。
- ItemWriter: 加工済みのデータをDBへ保存したり、別ファイルへ書き出したりする。
この役割分担が明確なおかげで、「読み込み元がCSVからDBに変わったけれど、加工ロジックは変えたくない」といった変更に柔軟に対応できるわけです。
最小構成で動かす:Spring Batchの環境構築と基本実装
Spring Batchは高機能ゆえに設定項目が多いと思われがちですが、Spring Bootのオートコンフィギュレーション(自動設定)を使えば、驚くほど簡単に始められます。実際に動く最小限の構成を見ていきましょう。
Spring Bootでの依存関係設定
まずは、build.gradle または pom.xml に必要な依存関係を追加します。Spring Initializrでプロジェクトを作成する際に「Batch」と「H2 Database」を選択するのが一番手っ取り早いです。
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-batch'
runtimeOnly 'com.h2database:h2'
testImplementation 'org.springframework.batch:spring-batch-test'
}ここでH2 Databaseなどのデータベースを含めているのは、Spring Batchがジョブの実行状況を管理するために、専用のテーブル(メタデータテーブル)を必要とするからです。このテーブルがあるおかげで、「さっき失敗したジョブの続き」をフレームワークが認識できる仕組みになっています。
なお、上記はSpring Boot 3.x系の記法です。Spring Boot 4.0でも同じスターターが利用可能ですが、Java 17以上が必須となります。
【Spring Boot 3対応】設定時の2つの注意点
Spring Boot 3以降(4.0含む)では、従来と異なる挙動が2点あります。把握しておかないと、動かない原因がわからず時間を溶かします。
① @EnableBatchProcessing は原則不要
Spring Boot 3では自動設定(Auto Configuration)が強化されたため、@EnableBatchProcessing を付けると逆に自動設定が無効になります。特別な理由がない限り、このアノテーションは付けないのが推奨です。
② 複数ジョブがある場合は起動対象を明示する
プロジェクトに複数のJobが定義されている場合、起動するJobを application.properties で明示する必要があります。
# 起動するジョブ名を指定(Spring Boot 3から推奨)
spring.batch.job.name=myFirstJobシンプルなJobを1つ作ってみる
次に、JavaのコードでJobとStepを定義します。Spring Batch 5以降(2026年5月時点の最新は6.0)では、JobBuilder や StepBuilder を使った流れるようなインターフェース(Fluent API)で記述するのが主流です。
@Configuration
public class SimpleBatchConfig {
@Bean
public Job myFirstJob(JobRepository jobRepository, Step myFirstStep) {
return new JobBuilder("myFirstJob", jobRepository)
.start(myFirstStep)
.build();
}
@Bean
public Step myFirstStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("myFirstStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("Hello, Spring Batch!");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
}よりシンプルな「Tasklet(タスクレット)」方式を使いました。単純な1回限りの処理(ログ出力やファイル削除など)には、この方式が最適です。
実行結果とメタデータテーブルの確認方法
プログラムを実行すると、コンソールにログが流れます。しかし、Spring Batchの本当の凄さはログではなく、データベースの中にあります。自動的に作成される BATCH_JOB_EXECUTION や BATCH_STEP_EXECUTION といったテーブルを覗いてみてください。
そこには、ジョブがいつ開始され、いつ終了したか、成功したのか失敗したのかという詳細な履歴が刻まれています。この履歴が残っているからこそ、私たちは「昨晩のバッチはどこまで進んだのか」をSQL1本で正確に把握できるのです。管理画面を自作する際も、これらのテーブルを参照するだけで、高度なモニタリング機能が実現できます。
Spring Batchのエラー制御とリカバリ機能
プロの現場でSpring Batchが「最強」と言われる所以、エラー制御とリカバリ機能を掘り下げます。実務では100%成功するバッチは存在しません。外部APIが落ちていたり、想定外のデータが混じっていたりするのは日常茶飯事だからです。
トランザクション管理とロールバックの仕組み
Spring BatchのChunkモデルでは、トランザクションがChunk単位で制御されます。例えばChunkサイズが100に設定されている場合、101件目でエラーが発生すると、101件目から200件目までの処理がロールバックされます。
しかし、1件目から100件目までのデータはすでにコミットされているため、データベースに残ります。これが「最初からやり直す必要がない」理由です。この挙動を正しく理解していないと、エラー時にデータを二重に登録してしまったり、どこまで処理が完了したか分からなくなったりするので注意が必要です。
リトライとスキップ設定の考え方
一時的なネットワークエラーであれば「少し待ってからやり直す(リトライ)」、特定のデータ形式が不正なら「そのデータだけ飛ばして次へ進む(スキップ)」という制御が、設定だけで実現できます。
.stepBuilder("myStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(reader())
.processor(processor())
.writer(writer())
.faultTolerant() // 耐障害性を有効化
.retryLimit(3) // 3回までリトライ
.retry(DeadlockLoserDataAccessException.class) // デッドロック時にリトライ
.skipLimit(10) // 10件までならスキップを許容
.skip(FlatFileParseException.class) // パースエラー時にスキップ
.build();このように、例外の種類に応じて「リトライすべきか、スキップすべきか」を柔軟に定義できます。これにより、些細なエラーでジョブ全体を止めることなく、完走率を高めることが可能です。
ジョブの再実行(リスタート)をどう扱うか
バッチが致命的なエラーで停止した場合、原因を修正してから再実行します。この際、Spring Batchはメタデータテーブルを参照し、未完了のStepから自動的に再開してくれます。
これを実現するためには「JobParameters(ジョブパラメータ)」の設計が重要です。同じパラメータでJobを実行しようとすると、Spring Batchは同一パラメータの実行を「前回の続き」とみなします。もし、最初から新しく実行したいのであれば、実行日時のタイムスタンプなどをパラメータに含めて、別の実行インスタンスとして認識させる必要があります。
Spring BatchのDB連携とファイル処理の実践例
実務で最も多いパターンは、ファイルの読み込みとDBへの登録です。自力でJavaのFileクラスやJDBCを直接触るのは卒業しましょう。Spring Batchには、長年の知恵が凝縮された標準コンポーネントが用意されています。
CSVファイルを読み込んでDBに登録する流れ
CSV読み込みには FlatFileItemReader を使用します。このクラスは、カンマ区切りのパースだけでなく、特定の行をスキップしたり、不正な形式の行を検知したりする機能が備わっています。
読み込んだデータは、JdbcBatchItemWriter を通じてデータベースへ書き込みます。このライブラリは内部的に PreparedStatement のバッチ更新を使用します。1件ずつINSERT文を発行するよりも圧倒的に高速で、ネットワークの往復回数を減らすことが大量データ処理におけるパフォーマンス向上の鉄則です。
データベースから取得して加工・出力するパターン
逆に、DBからデータを抽出して加工し、別のDBやファイルへ出力するパターンも頻出します。この際に重宝するのが JdbcPagingItemReader です。
100万件のレコードを一度に SELECT して ResultSet を保持し続けるのは危険です。ページングリーダーを使えば、SQLの OFFSET と LIMIT (あるいは同様の仕組み)を利用して、Chunkサイズに合わせて少しずつデータを取得してくれます。どんなに大量のデータがあっても、アプリケーションのメモリ使用量を一定に保てます。
大量データ処理で気をつけるポイント
大量データを扱う際は、ログの出しすぎに注意してください。100万件の処理で1件ごとに詳細なログを吐いていると、ディスクを圧迫するだけでなく、I/O待ちが発生して処理時間が劇的に伸びてしまいます。
Chunkの節目で進捗状況を出力する程度に留め、詳細なデバッグログは必要な時だけ出すように設定すべきです。また、処理対象の「抽出条件」に適切なインデックスが貼られているかも、確認必須です。インデックスがないだけで、バッチの実行時間が10分から10時間に伸びることも珍しくありません。
Spring Batch開発でよくあるつまずきと解決策
Spring Batchを使い始めると、必ずと言っていいほどぶつかる壁があります。それらはフレームワークの仕様によるものが多いのですが、仕組みさえ分かれば対処は簡単です。私の失敗経験から得た「転ばぬ先の杖」を共有します。
Jobが再実行できない理由と対処法
「修正して動かしたのに JobInstanceAlreadyCompleteException が出て動かない!」という叫びを何度聞いたことか。これは、Spring Batchが「このパラメータでのジョブは、以前に成功して終わっているから二度と動かさないよ」と親切(?)に教えてくれている状態です。
開発中に何度も同じジョブを試したい場合は、パラメータに System.currentTimeMillis() などを追加して、毎回「新しいジョブ」として認識させるのが手っ取り早いです。しかし、本番環境では「同じ日の集計を二重に行わない」というガードレールになるため、この仕様はむしろ頼もしい味方になります。
Chunkサイズはどう決めるべきか
Chunkサイズをいくつにするかは、バッチ設計における永遠のテーマです。小さすぎるとコミット回数が増えてオーバーヘッドが大きくなり、大きすぎるとメモリを圧迫し、エラー時のロールバックの影響範囲も広がります。
一般的には「100〜1,000」程度から始めるのが無難です。まずは500くらいで試してみて、ボトルネックがI/Oにあるのか、CPUにあるのかを見極めながら調整していきます。正解はありませんが、迷ったら「安定性」を優先して小さめに設定することを、私自身の苦い経験から強くおすすめします。
実際に私が経験したケースでは、chunk sizeを1,000に設定した状態で本番リリースしたところ、大量データ処理時にOutOfMemoryErrorが発生しました。原因調査に2時間かかりましたが、修正自体はchunk sizeを100に変更するだけで5分で完了。「設定値1つでシステムが止まる」という教訓は、今でもバッチ設計時の最初の判断基準になっています。
本番運用を意識したログ設計
バッチのログは、後から追跡可能でなければ意味がありません。Spring Batchが提供する StepExecution オブジェクトには、読み込み件数、書き込み件数、スキップ件数などの統計情報が含まれています。
これを各Stepの終了時にログ出力するように設計しておくと、「予定していた1万件のうち、9,950件が成功し、50件がデータ不備でスキップされた」といった状況が瞬時に把握できます。障害が起きたときに真っ先に知りたいのは「どのデータがダメだったのか」と「どこまで終わっているのか」ですからね。
Spring Batchのテストをどう書くか
「バッチのテストってどう書けばいいの?」という疑問は、現場でよく聞きます。実は Spring Batch には専用のテストサポートが用意されており、@SpringBatchTest アノテーションを使えば簡単にジョブ単体テストが書けます。
@SpringBatchTest
@SpringBootTest
class MyJobTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Test
void testJob() throws Exception {
JobExecution execution = jobLauncherTestUtils.launchJob();
assertThat(execution.getStatus()).isEqualTo(BatchStatus.COMPLETED);
}
}@SpringBatchTest を付けると、JobLauncherTestUtils(ジョブ起動ユーティリティ)と JobRepositoryTestUtils(テスト後のメタデータクリーンアップ)が自動でBeanとして登録されます。テスト間でジョブの実行履歴が干渉しないよう、各テスト後に jobRepositoryTestUtils.removeJobExecutions() でクリーンアップするのがお作法です。
よくある質問(FAQ)
Q: Spring BatchとSpring Bootの違いは?
Spring Bootはアプリケーション実行の基盤、Spring Batchはバッチ処理専用のフレームワークです。Spring Batchはチェックポイントによる再開やChunk単位のトランザクション制御など、「失敗を前提とした設計」を標準で提供します。
Q: Chunkサイズの推奨値は?
100〜1,000件から始めるのが一般的です。小さすぎるとコミットのオーバーヘッドが増え、大きすぎるとメモリ圧迫やロールバック範囲の拡大につながります。まず500件で試し、I/OとCPUのどちらがボトルネックかを見極めて調整してください。
Q: Spring Batchでスケジュール実行するには?
Spring Batch自体にスケジューリング機能はありません。OSの cron、Javaの Quartz、Spring の @Scheduled と組み合わせてジョブを起動するのが一般的です。
Spring Batchを使いこなすための次のステップ
ここまで来れば、Spring Batchの初級者から中級者への扉を開けています。最後に、さらに学びを深めるための道標を示します。
スケジューラとの連携方法
実は、Spring Batch自体には「毎週月曜の朝9時に実行する」といったスケジューリング機能はありません。それはSpring Batchの責務ではないからです。
Spring Batchの起動には、外部のスケジューラと組み合わせるのが一般的です。
個人・小規模開発向け:
- OS標準の
cron - Javaの
Quartz Spring Task Scheduling(@Scheduled)
エンタープライズ向け:
- JP1 / Systemwalker(オンプレミス)
- AWS Batch(クラウド)
いずれもコマンドライン経由でSpring Batchをキックする形が一般的です。
並列処理・パフォーマンスチューニングの考え方
シングルスレッドでの処理に限界が来たら、並列化を検討します。Spring Batchには、1つのStepを複数のスレッドで分割して処理する「マルチスレッドStep」や、データを複数のワーカーに分散して処理させる「パーティショニング」という強力な機能が備わっています。
ただし、並列化は魔法ではありません。データベースのロック競合や、実行順序の制御など、難易度は格段に上がります。まずは処理ロジックの効率化(無駄なSQLを叩いていないか等)を徹底し、それでも間に合わない時の「最終手段」として並列化を考えるのが、設計上の正しい順序です。
学習ロードマップとおすすめ公式ドキュメント
Spring Batchは2007年の初版リリースから約19年の歴史を持つフレームワークなので、ネットには古い情報も散見されます。最も信頼できるのは、Springの公式リファレンスガイド(docs.spring.io/spring-batch/reference/)です。英語ですが、最新の記法や非推奨になった機能を確認するには欠かせません。
まずは公式の「Getting Started Guide」(spring.io/guides/gs/batch-processing/)にあるチュートリアルを動かしてみることから始めましょう。その後、ソースコードを追いかけて TaskletStep や ChunkOrientedTasklet の中身を覗いてみると、トランザクション制御の仕組みが体感でき、理解がグッと深まります。